


GPTs Don't Use a Database
ChatGPT isn't looking up facts for you.


The most common misconception people have about ChatGPT is that when you ask it a question, it is in some way searching a database for an answer and returning it to you. The truth is that ChatGPT, like all language models, has no such database. Models don’t typically even use the internet at all. All knowledge that the models have learned is stored (mysteriously) in the model “parameters” – billions of numbers discovered through the training process that have little human interpretation.
In fact, it is generally unknown how (or whether it is possible) to get back the training dataset from the model’s parameters. Even worse, researchers often do not know where – even roughly – in that over 100 gigabyte file any particular bit of knowledge is stored. Your guess is as good as an expert’s in determining where a model stores “Joe Biden is the President of the United States.”
That we designed these models but still have little understanding of how they store knowledge strikes people as impossible. To try and explain how this fact is possible, I’ll do my best to explain terms like “training” and “parameters” in the context of the process for creating large language models.
Like the human brain, we have some intuition about how it might work, but the inner-workings of memory are unknown.
What are model parameters?
You have probably seen at least one kind of model before – the “line of best fit.” For example, suppose we were trying to predict home price from square feet. The plot below shows square footage on the x-axis and home-price on the y-axis. Shown is the line of best fit (the linear regression). While the relationship isn’t perfect, we can make a reasonable guess at the home price based on square feet by using the line’s equation: Price = 43.10 * (Square Feet) + 3226.44 (recall y=mx+b).
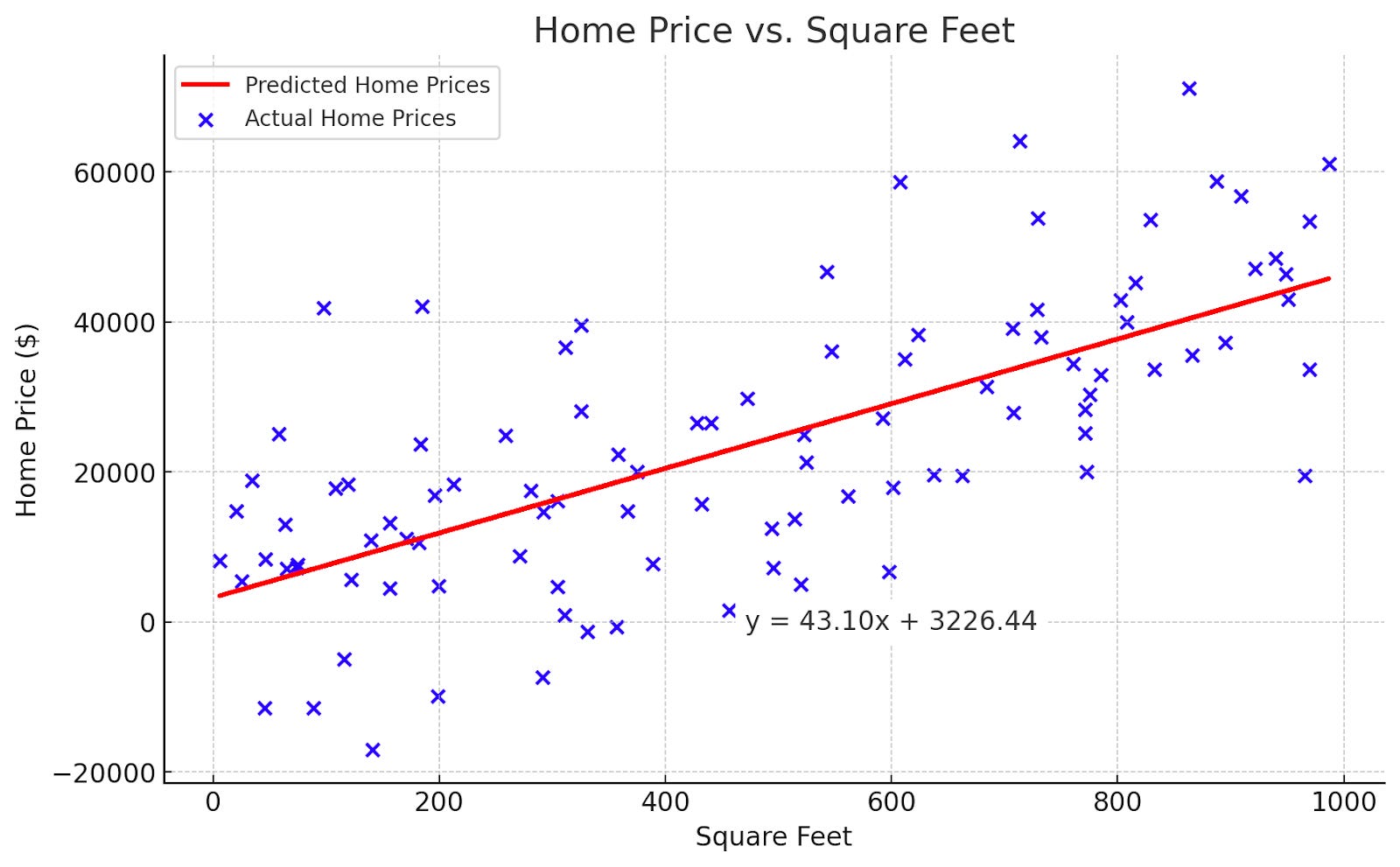
This predictive model has two parameters – the numbers 43.10 and 3226.44. The first number tells us that, in the dataset (known home-price and square-feet pairs), an additional square foot raises a home’s price on average by $43.10.
A large language model does a similar task, except instead of square feet on the x-axis, the input variable is a numerical representation of text. The y-axis (the thing being predicted) is the next word (or, in AI-jargon, token, which includes things like punctuation or word-fragments). Don’t get hung up on the idea that words are not numbers: we can switch between the two through a “tokenization” and “embedding” process, which is not covered here.
Our linear model involved one multiplication (43.10 * Square Feet) and one addition (... + 3226.44). In a large language model, there are many more additions, subtractions, multiplications, and divisions. The exact formula is not covered here, but rest assured that it is straightforward for a computer to calculate with enough processing power.
The Objective
When a language model “generates” text, it is repeatedly predicting the next word in the sequence in the same way our linear regression tries to predict home prices.
Each prediction is added to the input text, and the model again predicts the following word. The process is the same as if you typed out a text on your phone and kept hitting the auto-complete suggestion over and over. Large AI models are just a lot more sophisticated than the model doing auto-complete on your text messages.
Fundamentally, the language model is just trying to predict the next token. The model is not too dissimilar from our linear regression above, except it has many more than just two parameters that it can add and multiply together. In fact, it could have as many as a trillion.
Training
In the above example, the process of determining the two parameters of our model from the training data (the blue X’s) is called training. For a simple linear model, there are many ways to do the training process.
One simple way to find our line of best fit would be to try out a bunch of different lines. At each step, we could compare our new random line to a previous line and throw away whichever is worse. After enough tries, we would end up with a reasonably good line.
Training large language models is not too different. We continually make small (partially random) changes to our parameters and test them against a portion of the dataset. The final result is the combination of parameters that perform our task best once the training budget has been spent.
Where is the knowledge?
How is it possible that the model knows so much without referencing any database? The answer is that predicting text requires knowledge, so our next-token prediction engine will predict tokens consistent with the nature of the universe. For example, if we give the model “The sky is” and ask for a continuation, the next word might be “blue”, which is both factually correct and the most likely next word.
No one explicitly programmed into the model the fact that the sky is blue. Nevertheless, in order to predict text effectively, that knowledge has to be encoded by the parameters in some way. The result of all those multiplications, additions, and divisions happened to be the right answer. Recovering which parameter(s), out of a trillion, gave the model the correct answer is like finding a needle in a haystack.
Conclusion
The best analogy is probably the human brain: you can think of the knowledge it has picked up as what it has memorized – correctly or incorrectly. For precise figures or obscure facts, language models, like humans, could often benefit from a real reference.